机器学习房价预测实战案例:输入数据集,train和test分别是训练集和测试集,关注房价分布,剔除离群样本;进行特征工程,训练回归模型,stacking 集成学习以及多模型线性融合。
”python 机器学习 回归 集成学习 开发语言“ 的搜索结果

1.背景介绍 机器学习是一种人工智能的分支,它使计算机能够从数据中学习并提取有用的信息。...随着计算机技术的发展,机器学习在各个领域得到了广泛应用,如医疗诊断、金融风险评估、自然语言处理等。 Pyth...
data = [{"city":"北京","temperature":100},{"city":"上海","temperature":60},{"city":"深圳","temperature":30}]data = [{"city":"北京","temperature":100},{"city":"上海","temperature":60},{"city":"深圳",...
通过使用Python和它的机器学习库,我们涵盖了一些最常用最知名的机器学习算法(knn最近邻,k-means聚类,支持向量机),了解了一种强有力的集成方法(随机森林),涉及了一些其他机器学习支持方案(降维,模型验证...
内容介绍 在如今这个处处以数据驱动的世界中,机器学习正变得越来越大众化。它已经被广泛地应用于不同领域,如...用最火的Python语言、通过各种各样的机器学习算法来解决实际问题! 书中介绍的主要问题如下。 探...
时间序列预测是一种基于时间序列数据的预测方法,通常用于预测未来某个时间点的数值。在Python中,可以使用多种库和工具进行时间序列预测,例如ARIMA、Prophet等。
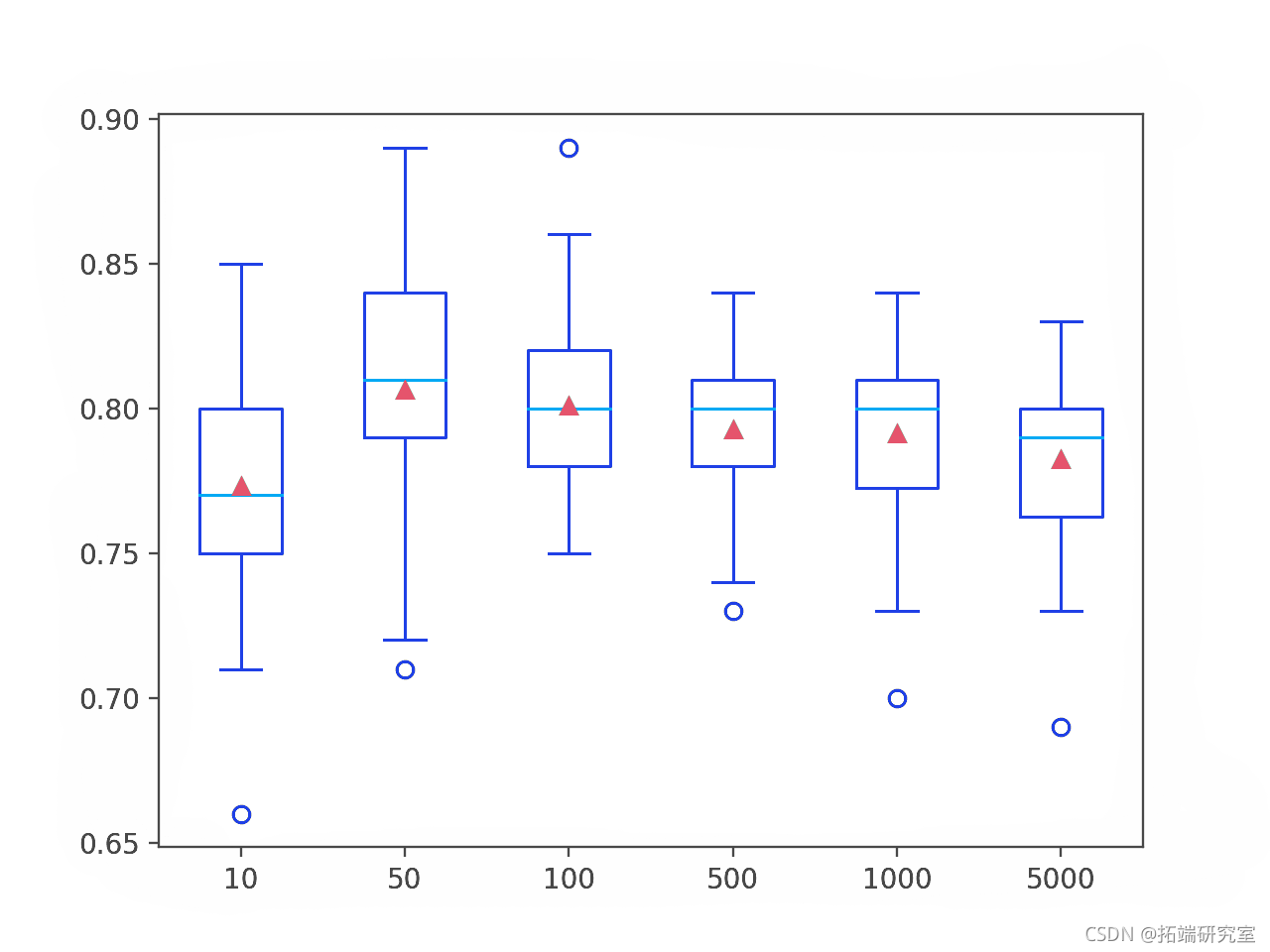
目录 走进XGBoost 什么是XGBoost? XGBoost树的定义 ...n_estimators(学习曲线) max_depth(学习曲线) 调整max_depth 和min_child_weight 调整gamma 调整subsample 和colsample_bytree 调整正则
根据输入数据是否具有“响应变量”信息,机器学习被分为“监督式学习”和“非监督式学习”。“监督式学习”即输入数据中即有X变量,也有y变量,特色在于使用“特征(X变量)”来预测“响应变量(y变量)”。“非监督...


在本文中,我们介绍了Python机器学习的一些基本概念和常用库和框架。我们还提供了一些常用的人工智能算法的Python实现示例,例如线性回归、决策树、神经网络等。如果你想深入了解Python机器学习,我们建议你学习更多...
第一个机器学习小项目,鸢尾花分类是机器学习领域中的一个经典示例,也是一个适用于入门级学习者的 "Hello World" 项目。这个项目使用鸢尾花数据集,其中包含了三个不同种类的鸢尾花:Setosa、Versicolor 和 ...
Python机器学习实战:使用机器学习进行时间序列分析 1.背景介绍 1.1 时间序列分析概述 时间序列分析是一种研究随时间变化的数据的统计技术。它广泛应用于金融、经济、气象、工业生产等诸多领域,旨在从历史数据中发现...
本文将介绍如何使用Python构建机器学习模型的API服务,并提供案例代码作为示例。首先,我们需要选择并训练一个适当的机器学习模型。这可能涉及数据收集、预处理、特征工程和模型训练等步骤。在本文中,我们将以一个...
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本...Python 机器学习是利用 Python 编程语言中的各种工具和库来实现机器学习算法和技术的过程。



机器学习、深度学习、LLM、数据结构算法专栏目录与整理,方便查找与阅读。

回归是指要预测的特征包含连续值。回归是指通过分析其他自变量之间的关系来预测因变量的过程。有几种已知的算法可以帮助提升这些关系以更好地预测值。在本教程中,我们提供了回归算法的高级概述,并展示了如何使用 ...
本书为我们提供了机器学习设计过程的坚实基础,能够使我们为特定问题建立起定制的机器学习模型。我们可能已经了解或使用过一些为解决常见问题的商用机器学习模型,例如垃圾邮件检测或电影分级,但是要着手于解决更为...

1.1 人工智能概述 1.2 什么是机器学习 1.3 机器学习算法分类 1.4 机器学习开发流程
参考链接: Python中的逻辑门 ...用最火的 Python 语言、通过各种各样的机器学习算法来解决实际问题! 书中介绍的主要问题如下。 探索分类分析算法并将其应用于收入等级评估问题使用预测建模并将其应用
一、线性回归 思路:建立预测值与真实值之间的误差方程,而所有数据的误差值服从独立同分布的高斯分布,为了使预测值更接近真实值,即当权重为多少时,使偏置最小,关于权重的似然函数,进而求对数似然函数的极大值...

推荐文章
- Unity3D 导入资源_unity怎么导入压缩包-程序员宅基地
- jqgrid 服务器端验证,javascript – jqgrid服务器端错误消息/验证处理-程序员宅基地
- 白山头讲PV: 用calibre进行layout之间的比对-程序员宅基地
- java exit方法_Java:如何测试调用System.exit()的方法?-程序员宅基地
- 如何在金山云上部署高可用Oracle数据库服务_rman target sys/holyp#ssw0rd2024@gdcamspri auxilia-程序员宅基地
- Spring整合Activemq-程序员宅基地
- 语义分割入门的总结-程序员宅基地
- SpringBoot实践(三十五):JVM信息分析_怎样查看springboot项目的jvm状态-程序员宅基地
- 基于springboot+vue的戒毒所人员管理系统 毕业设计-附源码251514_戒毒所管理系统-程序员宅基地
- 【LeetCode】面试题57 - II. 和为s的连续正数序列_leet code 和为s的正数序列 java-程序员宅基地